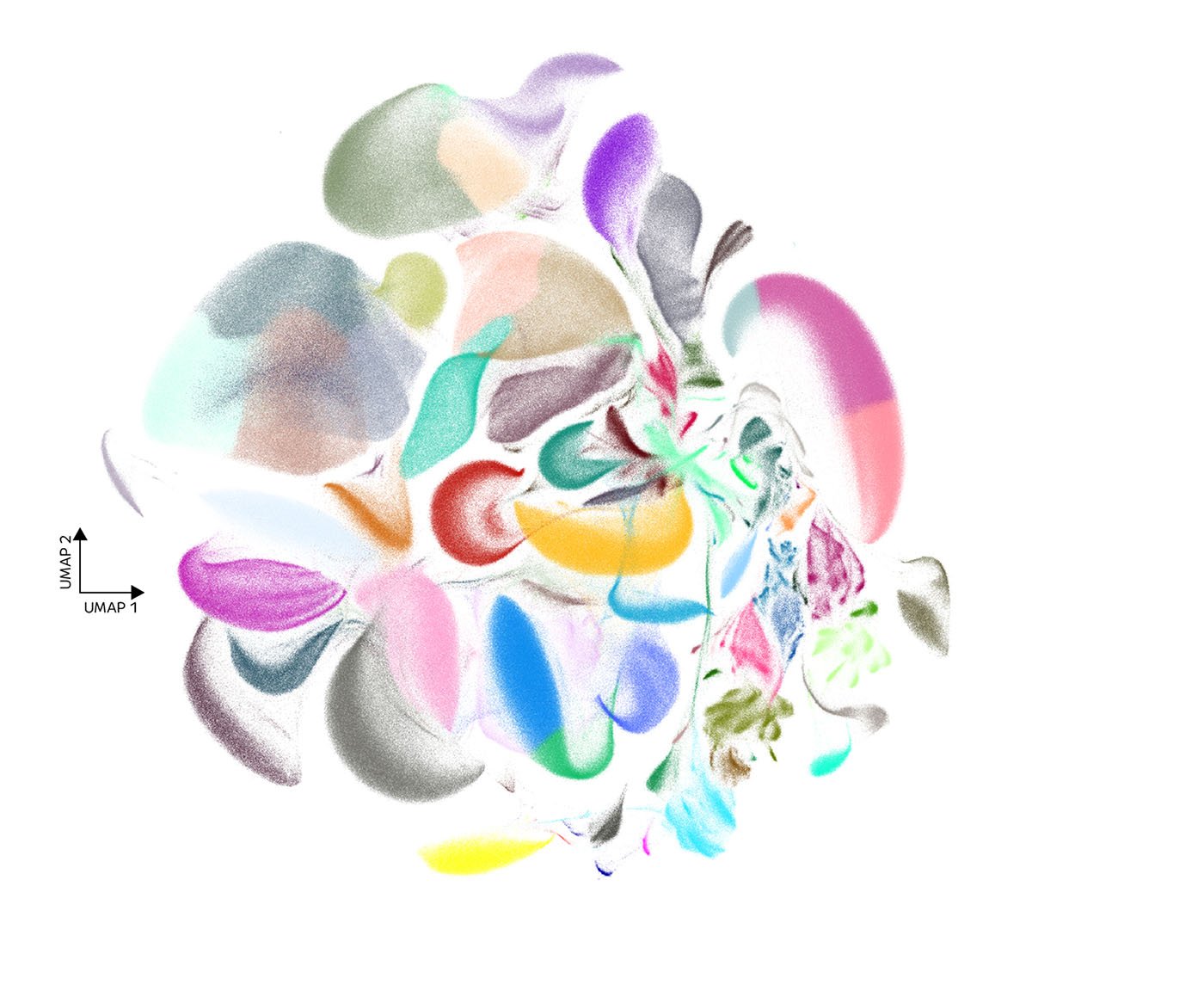
Single-cell RNA-seq (scRNA-seq) has spent the past decade maturing into a foundational technology. Over that time, the technology has both laid the foundation for building cell atlases and allowed exploration into how cells within the same tissue can behave differently, or how certain diseases can arise from subtle cellular differences.
“It’s kind of crazy that we used to do bulk measurements,” Serge Saxonov, PhD, CEO of 10x Genomics, told GEN at the AACR meeting in April. “Biology happens at the level of single cells—not weird mixtures of them.”
Over that same time, the amount of single-cell data being generated has grown both cumulatively and per experiment. The largest project in the field has been driven by the International Human Cell Atlas Consortium (HCA), founded in 2016. Since its inception, the HCA has grown into a global and grassroots collaborative consortium of nearly 4000 members that hail from more than 100 countries. The group’s goal is to build a comprehensive reference map of human cells.

Co-founder, HCA
“There is a vast amount of data in the human cell consortium,” noted Sarah Teichmann, PhD, professor at the University of Cambridge and Cambridge Stem Cell Institute, and one of the co-founders of the HCA (together with Aviv Regev, PhD, currently executive vice president and head of Genentech Research and Early Development), during “The State of Multiomics” virtual summit held earlier this year. “There are over a hundred million cells from dozens of tissues around the body.”
“We’re at a point,” Teichmann continued, “where we can start to assemble the data sets and provide reference atlases for different tissues, different organs, different systems around the body.”
This year’s HCA annual meeting, held in Singapore in June, brought together 63 speakers and over 600 participants from 47 countries, making it one of the largest gatherings to date. “This peak in commitment and visibility coincides with newly introduced focus areas, following the near completion of most healthy single-cell organ atlases,” notes Holger Heyn, PhD, research professor at ICREA in Barcelona and the co-founder and CSO at Omniscope. “Spatial atlas building, a pivot towards the inclusion of global diseases, and a continued emphasis on diversity were center stage at this meeting and will define the activities of the project moving forward, shaping both its scientific priorities and its global collaborative framework in the years to come.”

Vice President Scientific Strategy and Partnerships
CZI
The HCA’s progress, momentum, and success are a bellwether for the advancements the single-cell field is making elsewhere. “Single-cell methods in biology are at this point of democratization, which is really exciting,” says Jonah Cool, PhD, Vice President, Scientific Strategy and Partnerships, Chan Zuckerberg Initiative (CZI). Cool is the lead for CZI’s single-cell biology program, a large interdisciplinary program that blends internal and external technology development funding for fundamental research. “It’s moving from what was once a small niche field into increasingly a workflow that is being used by researchers around the world.”
There is a clear recognition, he says, of the power of single-cell technologies in basic discovery and research. But the technology is growing and moving beyond that into new applications such as drug development and modeling AI. And that is where things start to get really exciting.
Adding some zeros
Single-cell datasets have increased, thanks largely to the combination of decreasing sequencing costs (see sidebar) and the expansion of novel technologies that are commercially available.
But the past year seems to have brought an explosion of big projects. Last fall, Scale Bio’s 100 Million Cell Challenge made a splash. The idea—the brainchild of Giovanna Prout, president and CEO of Scale—was to inspire researchers to submit proposals for experiments that they have always wanted to do but couldn’t because of cost or logistics. The company, and its collaborators (CZI (funding), Ultima Genomics (sequencing), Nvidia (compute power), and BioTuring (access to their advanced analysis platform, BBrowserX)) collaborated to defray the costs of the projects. The 14 winners were announced in Denver, CO, at the American Society of Human Genetics meeting last fall. The initiative, which ended up drawing 147 different proposals totaling nearly one billion cells, from
researchers in 27 countries, showcased that there is a demand “for these really large-scale initiatives,” said Prout.
Then, last December saw the generation of “the largest single-cell dataset to date” by Parse Biosciences and Vevo Therapeutics (now Tahoe). The Tahoe-100M dataset comprises 100 million cells and covers 60,000 conditions, 1,200 drug treatments, and 50 tumor models. Tahoe plans to use the dataset to advance its artificial intelligence-based drug discovery efforts.
“The Tahoe project was done really quickly by utilizing tools we had in-house at super large scale,” explains Gilad Almogy, PhD, Founder and CEO of Ultima Genomics, which performed the sequencing for the project. “We generated the world’s largest single-cell dataset, and we did it only in a few weeks (from getting the libraries to finishing the sequencing).”
Around the same time, CZI brought everything up an order of magnitude when they announced the “Billion Cells Project”. CZI is no stranger to large
single-cell projects, given the establishment of their CELL by GENE Discover (CZ CELLxGENE)—a collection of tools for analyzing single-cell data—and their involvement with Scale’s Million Cell challenge. Continuing to push the envelope, CZI announced the new effort to generate a one billion cell dataset to fuel rapid progress in AI model development in biology. Original collaborators were 10x Genomics, Ultima Genomics, and researchers. Then, at the CZI Biohub NY Affiliate Symposium held this past April, a new Billion Cells Project partnership with Scale Bio was announced.
The scalability of Scale’s platform, notes Prout, makes it particularly useful for large projects like this “where you can run four million cells in one shot.” In the Billion Cells Project, the end user will run these experiments, so ease-of-use is also important.
Currently, the Billion Cells Project has scaled to collaborate with more than 10 leading labs and institutions across the country, with additional labs coming on board this year. Project leaders note that they are on track to generate nearly 500 million cells worth of data within the first year.
Also in February, the Palo Alto, CA-based Arc Institute joined the single-cell movement when they launched the Virtual Cell Atlas project to create a large-scale, AI-driven, single-cell virtual cell atlas. A few months later, a partnership with 10x Genomics and Ultima was announced to advance the project.
“I’m personally excited,” Saxonov told GEN about the project, “because I think it’s a new way of doing science, where you are being very systematic about measuring biology and genes and systematically building computational models with biology. Ultimately, the notion is you’re trying to simulate biology in a computer, which is kind of fantastical, but at the same time, not crazy anymore. And that puts you in really good stead to now start accelerating your research and accelerating drug development because these models provide a means for doing target discovery.”
Most recently, in June, the Wellcome Sanger Institute, Parse Biosciences, and the Computational Health Center at Helmholtz Munich announced a collaboration to build the foundation of a single-cell atlas focused on understanding and elucidating cancer plasticity in response to therapies, ultimately encompassing hundreds of millions of cells. Using novel organoid perturbation and AI platforms, the aim is to create a comprehensive dataset to fuel foundational drug discovery models and cancer research.
Scale it up
These recent big datasets are spawning new big datasets. “We’ve had a huge amount of interest in scaling up single-cell since we released the Tahoe-100M cell dataset,” notes Alex Rosenberg, PhD, co-founder and CEO of Parse Biosciences. It has “led to many different researchers and companies reaching out to recreate similar datasets.”
Parse developed the GigaLab to enable large-scale studies so that the researchers don’t necessarily need to support the infrastructure needed to run these single-cell experiments: they simply send their fixed cells to Parse.
Scale is something that, Saxonov says, 10x has always kept front and center. Indeed, 10X Genomics previewed a new product at AGBT this past February that is expected to launch later this year: a plate-based flex that will allow for more scale. There is no limit that he foresees in terms of how much they can increase. It’s much more, he explains, about managing the cost equation.
“As you drive down costs and improve ease of use, people will do more and more,” asserts Saxonov. “And that is what’s happening. And in fact, if you think about how the AI-modeling approaches are coming together, there is an inexhaustible need for high-quality data.”
“We may add another letter after that (meaning trillions). This is just the beginning!”
Data overload
With more cells comes more data. “Having these large data sets is obviously a massive opportunity in terms of the modeling of one modality at a time,” Teichmann explains. She adds that researchers are also modeling in the context of other modalities and building multimodal foundation models (like RNA-seq and ATAC, or RNA-seq and spatial). “It’s a very exciting time, and there are different technology developments that are coming together at this juncture. So that’s a lot of fun!”
But the increase in data also brings new challenges. Cool says that there is
“a lot of work to do on the modeling, the informatics, and even just the management of data sets of this size.”
Teichmann agrees that the analysis and the modeling of the data can be a bottleneck, especially with foundation models and generative AI and the large graphics processing unit (GPU) needed.

Part of the goal of the Billion-Cells Project, notes Cool, is to push the field in informatics. This happened early in the HCA; it was somewhat inconceivable to think of tool chains to deal with a million cells. But those tools have come a long way, he says. Now, they don’t break a sweat at a million, but they are going to break at a billion. “So, we want to advance the models, and we also want to keep pushing on data management and an infrastructure to make all that data useful to science broadly,” Cool asserts.
The computational tools must enter a new realm, agrees Teichmann. Luckily, the deep learning techniques and the generative AI techniques provide that toolkit and open an incredibly exciting time full of opportunities.
Five years from now
If Teichmann looks out five years, she sees a foundation model of the human body that can be asked many different questions. And if it’s integrated with disease and screening, there could be a kind of ChatGPT-like interrogation that goes beyond asking, “Where’s this gene expression?” and “Where’s this cell type?” Rather, one could ask questions like: What other genes does this gene depend on? What are the regulatory cascades? And ultimately, the information can be embedded with model organisms.
In five years, Cool predicts an ambitious, impactful set of models and methods that are accessible to allow people to test hypotheses or establish ground truth in their system. Given the rate of progress in this field, and the vision, he thinks that’s not far-fetched.
And single-cell is starting to move off campus; there are many small and large pharma companies adopting single-cell methods. One needs to look no further than Teichmann’s roles outside of the University of Cambridge—some of which include windows into biotech and pharma. (She serves as the vice president of translational research at GSK and the co-founder and CSO of Enso Cell Therapeutics, a private drug discovery company.)
This, she asserts, really hammers home how these technologies can be deployed in drug development in the context of clinical trials, disease phenotyping, screening, organoids, and so on. “I think we have only scratched the surface,” she notes.
Indeed, these large projects may be moving the field across the threshold, given the decreasing cost of sequencing, the expansion of technologies by single-cell technology companies, and healthy competition in the market. Single-cell researchers will continue to push the envelope—a trillion cells at a time.
The post The Single-Cell Club Is Rapidly Expanding appeared first on GEN – Genetic Engineering and Biotechnology News.